
In context: No one in the industry is too happy about completely relying on Nvidia's chips for AI training, although many companies feel they don't have a real choice. Apple, however, took a different path and appears to be pleased with the results: it opted for Google's TPUs to train its large language models. We know this because Cupertino released a research paper on the processes it used to develop Apple Intelligence features. That too represents a departure for Apple, which tends to play things close to the chest.
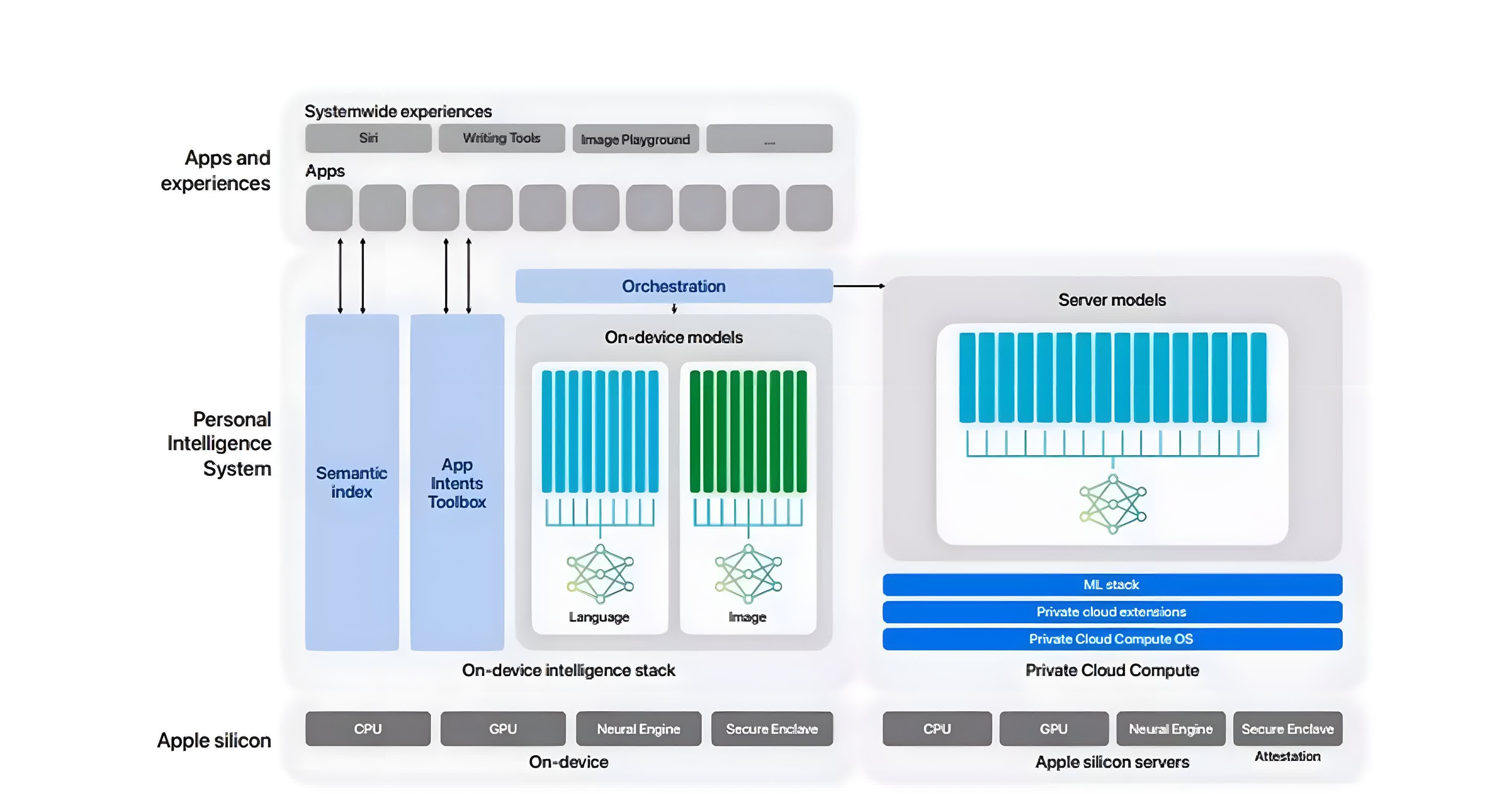
Apple has revealed a surprising amount of detail about how it developed its Apple Intelligence features in a newly-released research paper. The headline news is that Apple opted for Google TPUs – specifically TPU v4 and TPU v5 chips – instead of Nvidia GPUs to train its models. It is a departure from industry norms as many other LLMs, such as those from OpenAI and Meta, typically use Nvidia GPUs.
For the uninitiated, Google sells access to TPUs through its Google Cloud Platform. Customers must build software on this platform in order to use the chips.
Here is a breakdown of what Apple did.
The AFM-server, Apple's largest language model, was trained on 8,192 TPU v4 chips configured in 8 slices of 1,024 chips each, interconnected via a data-center network. The training process for AFM-server involved three stages: starting with 6.3 trillion tokens, followed by 1 trillion tokens, and concluding with context-lengthening using 100 billion tokens.
The AFM-on-device model, a pruned version of the server model, was distilled from the 6.4 billion parameter server model to a 3 billion parameter model. This on-device model was trained on a cluster of 2,048 TPUv5p chips.
Apple used data from its Applebot web crawler, adhering to robots.txt, along with various licensed high-quality datasets. Additionally, selected code, math, and public datasets were used.
According to Apple's internal testing, both AFM-server and AFM-on-device models performed well in benchmarks.
A few things of note. One, the detailed disclosure in the research paper is notable for Apple, a company not typically known for its transparency. It indicates a significant effort to showcase its advancements in AI.
Two, the choice to opt for Google TPUs was telling. Nvidia GPUs have been in extremely high demand and short supply for AI training. Google likely had more immediate availability of TPUs that Apple could access quickly to accelerate its AI development, which is already a late arrival in the market.
It is also intriguing that Apple found that Google's TPU v4 and TPU v5 chips provided the necessary computational power for training their LLMs. The 8,192 TPU v4 chips that the AFM-server model was trained on appear to offer comparable performance to Nvidia's H100 GPUs for this workload.
Also, like many other companies, Apple is wary of becoming overly reliant on Nvidia, which currently dominates the AI chip market. For a company that is meticulous about maintaining control over its technology stack, the decision to go with Google is particularly sensible.